
Du 11 et 14 septembre 2023, à Louvain, j’ai eu l’occasion de participer au congrès de l’IGELU (International Group of Ex Libris Users). Ce congrès, organisé par le club international des utilisateurs des logiciels d’Exlibris, a réuni des responsables ou administrateurs de systèmes d’information documentaire de bibliothèques du monde entier, et des directeurs et chefs de produits de la société Ex Libris. L’occasion pour les premiers d’effectuer un retour d’expérience sur des projets novateurs mis en place dans leurs établissements, et pour les seconds de communiquer sur les feuilles de route des logiciels documentaires. J’assistais pour ma part à ce congrès pour présenter le circuit de synchronisation pour la documentation électronique mis en place avec le SUDOC et, en tant que vice-président de l’ACEF (le club utilisateurs francophone), pour rencontrer les responsables produits d’Ex Libris.
Je vous propose une rapide synthèse des tendances marquantes et des évolutions à attendre sur nos applications dans les années à venir.
Le « Linked Open Data » arrive dans Alma
Cela faisait longtemps que l’on en discutait dans la communauté des utilisateurs : nous avons enfin pu avoir des éléments concrets concernant le déploiement du format de notices BIBFRAME dans Alma, et des exemples d’utilisation de ce format via la démonstration d’un prototype de moteur de recherche par entités, qui préfigure ce que pourrait devenir Primo.
À partir de 2024, il sera possible de cataloguer dans Alma en BIBFRAME. Ex Libris va intégrer, en parallèle de l’éditeur de métadonnées, l’éditeur Sinopia. Il est d’ailleurs déjà possible d’intégrer des notices nativement BIBFRAME dans Alma via API.
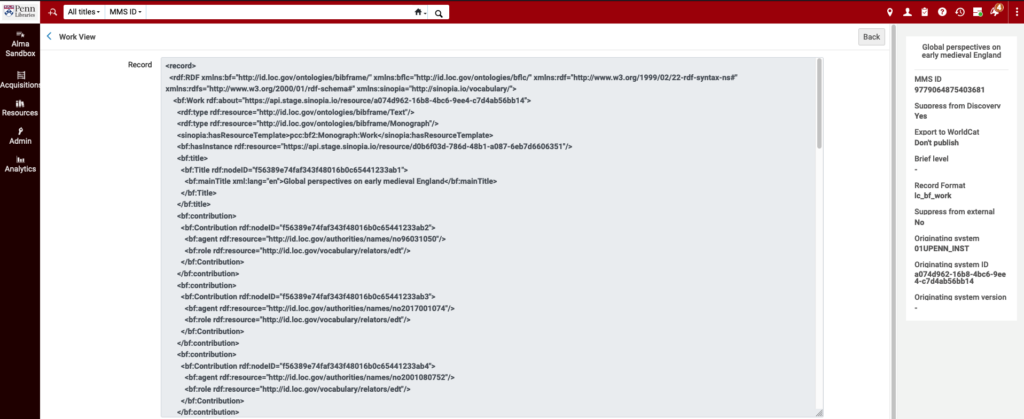
Ex-Libris garantit la coexistence de Marc et du format par entité dans un même catalogue. L’usage des URI dans les zones de lien permettra de mettre en place des relations entre des notices aux différents formats. Des outils de conversion permettront de passer des notices de Marc à BIBFRAME et inversement.
Du côté des interfaces, Ex Libris travaille sur un moteur de recherche par entités.
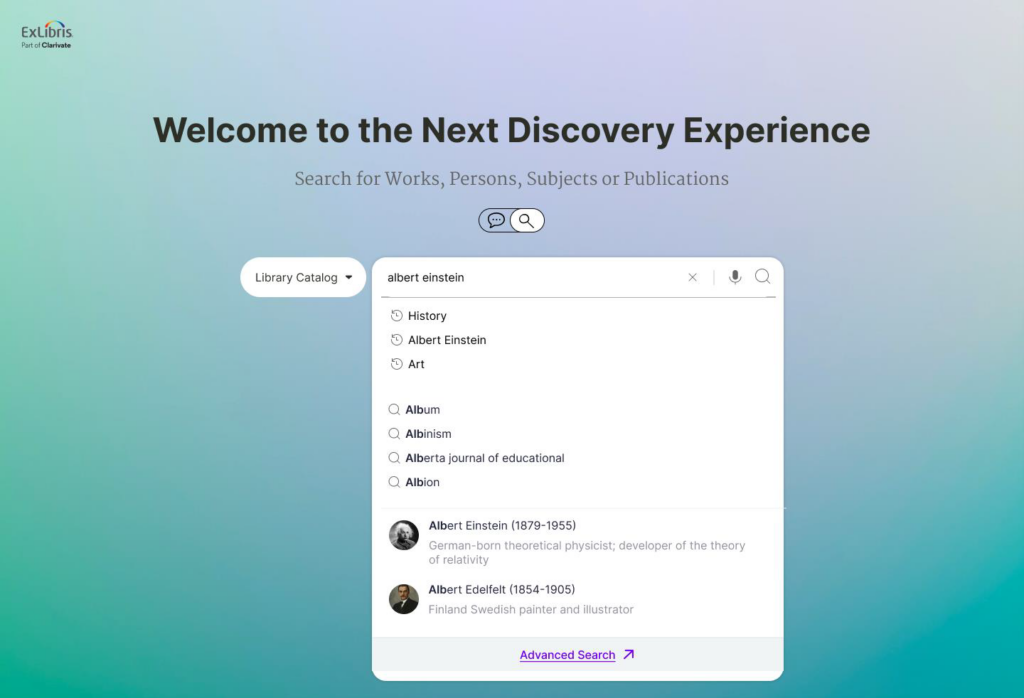
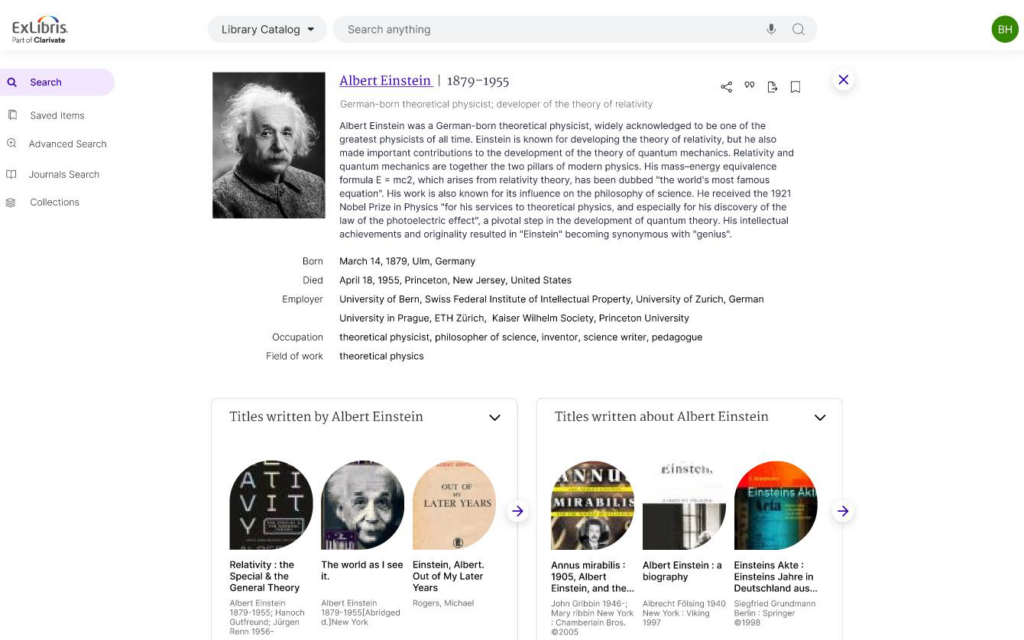
Cet outil n’est pour l’instant qu’à l’état de prototype et aucune date de mise en production n’a été évoquée.
En revanche, dès 2024, Primo VE exploitera les URI qui pourront être intégrées aux notices afin de proposer des fiches « auteurs » dans l’affichage détaillé des résultats.
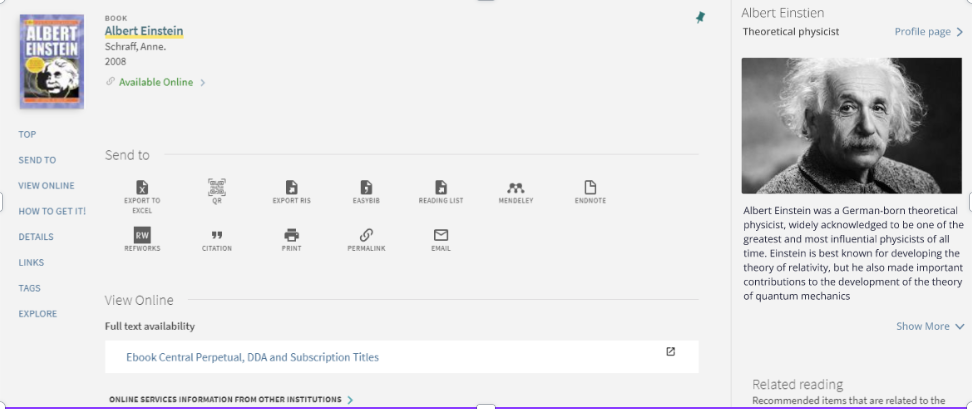
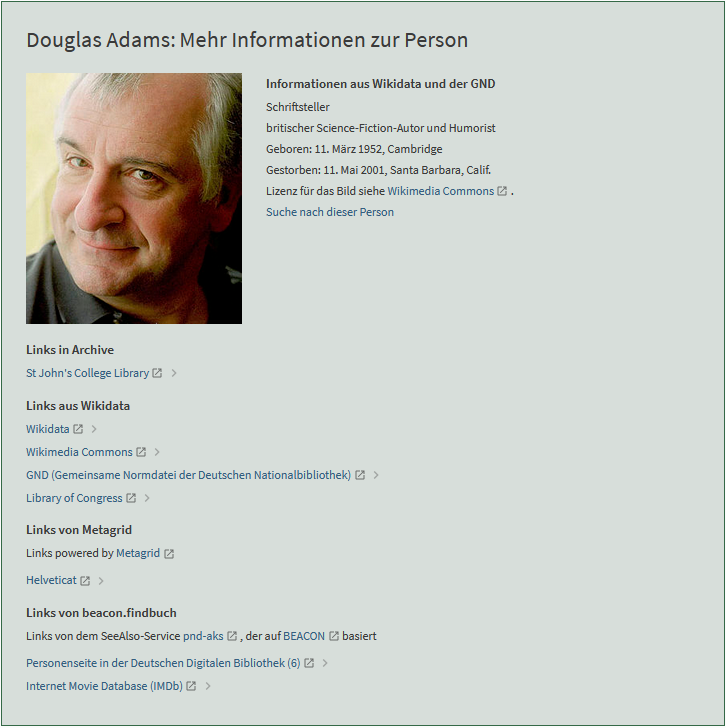
Certains établissements ont dès à présent développé des solutions pour enrichir leur catalogue Primo via les « linked data ». La bibliothèque de l’ETH à Zurich propose ainsi des fiches auteurs sous l’affichage détaillé de la notice dans Primo.
Ex Libris a fait le choix de BIBFRAME, à la demande de sa communauté d’utilisateurs, pour porter l’intégration des formats par entités dans son système de gestion. Ce choix-là ne correspond pas, pour l’instant, aux orientations prises par la Transition Bibliographique en France. Il faudra donc voir au cas par cas dans quelle mesure le futur format Unimarc-Entités-Relations (qui devra remplacer le format Unimarc au terme de la Transition Bibliographique) nous permettra de profiter des nouveaux services proposés dans Alma. Mais il est à craindre que nous ne puissions pas profiter de toutes les évolutions.
Vous prendrez bien un peu d’IA dans votre catalogue ?
Outil d’aide à la décision, amélioration de l’indexation ou moteur de recherche conversationnelle, l’intelligence artificielle était évoquée dans de nombreuses présentations.
Les conférences d’ouverture et de fermeture assurées par Koenraad Debackere, professeur en management de la technologie et de l’innovation à la faculté d’économie et de commerce de la KU Leuven, et Jeroen Baert, chercheur en sciences informatiques, montraient l’importance que prennent les IA dans le domaine de l’enseignement et de la recherche. Chaque intervenant a mis en avant la question de la définition des corpus utilisés pour l’entrainement des grands modèles de langues. En effet, de la pertinence des sources utilisées va dépendre la qualité des réponses fournies. D’autre part, comme en témoignent les récentes actions en justice collectives des auteurs états-uniens contre ChatGPT, l’usage de ces sources n’est pas sans poser des problèmes de droits d’auteurs. C’est sur cette question cruciale de constitution des corpus d’entrainement des IA que nous pouvons, en tant que spécialistes de l’information, jouer un rôle important.
Du côté de nos besoins métiers, toutes les présentations stratégiques d’Ex Libris mettaient l’IA au cœur des futures évolutions des logiciels. Ex Libris projette d’utiliser l’intelligence artificielle pour faire du contrôle qualité sur les données de la base de connaissance et de l’index central, pour améliorer les interfaces de recherche, ou encore nous fournir des outils décisionnels au sein d’Alma. Il s’agit pour l’instant plus de discours marketing et d’expérimentations que d’une réelle perspective inscrite dans les feuilles de route des produits. Mais le partenariat annoncé cet été entre Clarivate et la société AI21 Labs spécialisée dans le traitement automatique du langage naturel prouve que l’IA sera un axe majeur du développement des produits.
Nous avons d’ailleurs pu découvrir que les outils étaient disponibles pour créer dans nos bibliothèques des services basés sur l’IA via deux projets en l’état de prototype mais forts convaincants.
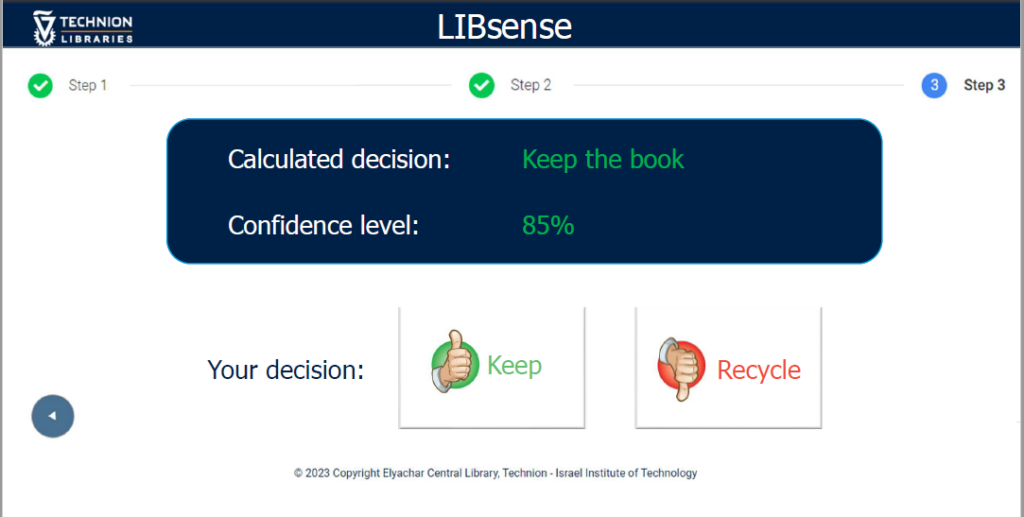
LIBsense de l’Israel Institute of Technology est une application qui s’appuie sur les APIs d’Alma et l’Intelligence Artificielle pour construire un moteur d’aide à la décision afin d’aider les bibliothécaires dans le choix de faire entrer ou non les documents dans les collections lors des traitements des dons. Concrètement, à partir d’une photographie de la couverture ou de la page de titre, l’application va extraire d’Alma les données d’usages du titre. Elle va se baser sur ces éléments et les décisions déjà prises par les bibliothécaires pour proposer ou non de conserver le document. Le bibliothécaire peut alors choisir ou non de suivre les recommandations. Son choix permettra ensuite d’améliorer le moteur de décision.
Ex Libris a aussi présenté un prototype fonctionnel de recherche conversationnelle. Il s’agit d’un grand modèle de langues (LLM) entrainé à partir des articles de la base ProQuest One Literature. Une interface à la ChatGPT permet l’interrogation en langage naturel. En plus de la réponse faite à l’utilisateur, le moteur de recherche propose des liens vers les sources utilisées pour construire la réponse.
La roadmap produits : sélection des fonctionnalités à attendre pour 2023-2024
Amélioration des interfaces
La modernisation de l’interface d’Alma va se poursuivre sur 2024 avec la refonte des interfaces de services aux lecteurs (prêt, retour), dans le courant de l’année 2024, et la modernisation des écrans de recherches et de résultats des titres (tous les titres, titres électroniques et titres physiques) prévue elle pour la fin 2024. En parallèle, des travaux ont été engagés avec six établissements pilotes pour moderniser l’interface de Primo. Les évolutions seront déployées progressivement dans l’interface existante.
Amélioration de la base de connaissance et de l’index central
Un des chantiers de l’équipe Content d’Ex Libris est d’améliorer le temps de mise à disposition des collections à partir du moment où un nouveau bouquet est identifié. En effet, chaque collection, avant d’être ajoutée à la KB, doit passer une série d’étapes de contrôle technique, de validation juridique et d’évaluation fonctionnelle avant d’être disponible pour activation dans Alma.

L’objectif pour Ex Libris est d’optimiser ce circuit et de mettre à disposition les mises à jour des bouquets déjà identifiés quotidiennement.
En parallèle, le travail sur l’amélioration de la qualité des données dans la base de connaissance, la zone communautaire et l’index central se poursuit. Avec 12 millions de notices dans la zone communautaire, et 5 milliards de notices dans CDI, Ex Libris cherche des stratégies pour identifier des corpus nécessitant le plus d’attention. Ils voudraient par exemple traiter en priorité les portfolios de livres électroniques les plus activés dans la KB. Cette stratégie a été fort critiquée, car elle pénaliserait les sources non anglophones.
Ex Libris voudrait aussi utiliser des sources alternatives d’enrichissement du catalogue communautaire. Sur ce sujet, l’ACEF portait une proposition émanant notamment des collègues belges d’enrichir les notices en français de la zone communautaire (CZ) par des notices en provenance du SUDOC. Ex Libris a marqué son intérêt pour la demande et nous espérons réussir à faire collaborer notre éditeur avec notre agence nationale afin d’améliorer la qualité des notices de documents en langue française.
Du côté de CDI, Ex Libris promet dès la fin d’année et le début 2024 de poursuivre l’amélioration du typage des documents et de proposer une normalisation des sujets dans les résultats et les index de recherche.
Autres améliorations à attendre
Du côté de la gestion de la documentation électronique, le nombre de consultations (en provenance du résolveur de lien) sera visible sous chaque portfolio ou titre électronique et à partir de l’analyse de chevauchement.
Il sera possible, à partir de Babord +, d’alimenter une sélection à partir d’un résultat de CDI.
Enfin, du côté des acquisitions, il sera possible de créer une ligne de bon de commande à partir du catalogue d’un site marchand à l’aide d’un bookmarklet.